
Controlling what search engines can and can’t crawl is an essential part of managing your online presence. One of the most effective ways to do this is using a robots.txt file. This plain text file tells search engines which parts of your website they can access and which they cannot, helping you guide traffic, protect sensitive content, and improve your site’s SEO.
In this blog, we’ll dive into the importance of a robots.txt file, how to create one, and how to customize it to suit your needs. Whether you’re a beginner or someone with experience managing websites, this guide will help you ensure your site is crawled effectively by search engines.


什麼是 Robots.txt 檔案?
A robots.txt 檔案 is a simple text file placed in the root directory of your website. Its purpose is to instruct web crawlers (such as Google’s Googlebot) on which parts of your site they can visit and index. Following the 機器人排除標準此檔案可協助您控制特定目錄或網頁的存取權,同時確保重要內容仍可供搜尋引擎編入索引。


例如,如果您的網站是 www.example.com, 您的 robots.txt 檔案應該位於 www.example.com/robots.txt.
Robots.txt 檔案如何運作?
A robots.txt file is made up of a series of rules, with each rule specifying whether a certain web crawler (called a “user agent”) can access specific parts of your website. The rules include commands like 不允許, 允許以及 網站地圖,可以限制或允許存取各種 URL。

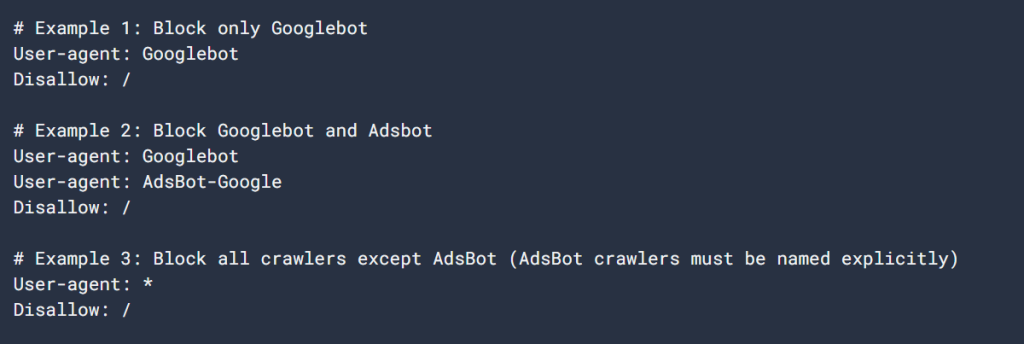
讓我們來看看 robots.txt 檔案的簡單範例:
User-agent:Googlebot
禁止:/nogooglebot/
User-agent:*
允許:/
網站地圖: https://www.example.com/sitemap.xml檔案的說明:
- Googlebot (Google’s crawler) cannot crawl any URL that starts with https://www.example.com/nogooglebot/.
- 所有其他使用者代理(以 *, which means “all crawlers”) can crawl the entire site.
- 本網站的網站地圖位址如下 https://www.example.com/sitemap.xml.
如果沒有 robots.txt 檔案,預設情況下所有爬蟲都可以存取整個網站。robots.txt 檔案會精簡這些權限。
為什麼需要 Robots.txt 檔案?

使用 robots.txt 檔案有幾個優點:
- 控制爬行:它允許您管理搜尋引擎抓取網站的哪些部分,減少伺服器的負載,並防止敏感內容被索引。
- 改善 SEO:您可以讓搜尋引擎爬蟲專注於您網站上最重要的網頁,確保它們索引正確的內容,以提高您的搜尋排名。
- 保護敏感內容:雖然 robots.txt 檔案無法防止敏感資料的存取,但它可以幫助隱藏私人頁面,讓搜尋引擎爬蟲無法讀取,例如登入頁面或管理區段。
如何建立 Robots.txt 檔案
建立 robots.txt 檔案很容易,您可以使用任何純文字編輯器,例如 記事本, 文字編輯, vi或 Emacs.避免使用 Microsoft Word 等文字處理器,因為它們可能會引入可能會干擾檔案正常運作的格式。
1. 建立檔案
開啟文字編輯器,儲存一個名為 robots.txt.確保編碼為 UTF-8 格式。
2. 新增規則
開始新增規則,指定規則適用於哪些使用者代理,以及允許 (或禁止) 抓取網站的哪些部分。
以下是如何封鎖所有網路爬蟲存取特定目錄的範例:
使用者代理:*
禁止:/private-directory/3. 上傳檔案
上傳 robots.txt 檔案到您網站的根目錄。例如,如果您的網站是 www.example.com, 檔案必須在 www.example.com/robots.txt.如果您不確定如何存取根目錄,請聯絡您的主機供應商。
4. 測試檔案
上傳檔案後,您可以開啟私人模式的瀏覽器,並導航至 https://www.example.com/robots.txt.如果您可以檢視檔案,表示檔案已成功上傳。
常見的 Robots.txt 規則
以下是一些在 robots.txt 檔案中常用的規則:
1. 阻止所有爬蟲進入整個網站


使用者代理:*
禁止:/此規則會阻止所有爬蟲存取整個網站。請謹慎使用此規則,因為它會阻止搜尋引擎索引您的內容。
2. 允許所有爬蟲存取整個網站


使用者代理:*
允許:/此規則允許所有網路爬蟲存取您的整個網站。如果您沒有在 robots.txt 檔案中指定任何規則,這是預設行為。
3.封鎖特定目錄
使用者代理:*
禁止:/private-directory/此規則會阻止所有爬蟲存取 /private-directory/.請記住,尾部的斜線表示目錄內的所有內容也是不允許的。
4. 允許特定目錄,封鎖其他目錄
使用者代理:*
禁止:/
允許:/public/此規則會封鎖整個網站的存取,除了 /public/ 目錄。當您想要將網站的大部分內容保密,但又允許特定的公開頁面被索引時,這就非常有用了。
5. 封鎖特定頁面
使用者代理:*
Disallow:/useless_page.html此規則會阻止所有爬蟲存取您網站上的特定頁面。
6. 指定網站地圖
網站地圖: https://www.example.com/sitemap.xml在您的 robots.txt 檔案中包含網站地圖,可協助搜尋引擎快速定位並抓取您網站上的所有重要頁面。
Robots.txt 檔案的最佳做法
建立您的 robots.txt 檔案時,請牢記下列最佳實務:
- 具體說明: Only block pages or directories you don’t want search engines to crawl.
- 使用適當的案例:規則是區分大小寫的,因此 禁止:/Private/ 和 禁止:/private/ 會封鎖不同的目錄。
- Don’t Use Robots.txt for Sensitive Data:robots.txt 檔案是公開的,任何人都可以存取。如果您有敏感的內容,例如登入頁面或管理區域,請使用適當的驗證方法來保護它們,而不是依賴 robots.txt。
- 定期更新:確保您的 robots.txt 檔案隨著網站結構的變更而保持更新。
如何測試並提交 Robots.txt 檔案

上傳您的 robots.txt 檔案後,您可以使用下列方式測試其有效性 Google 搜尋控制台的 robots.txt 測試器.此工具有助於確保您的檔案格式適當,並確保 Google 能正確解讀。
向 Google 提交您的 robots.txt 檔案:
- 前往 Google Search Console。
- 使用 Robots.txt 測試器 來驗證您的檔案。
- 一經驗證,Google 就會自動找到並使用您的 robots.txt 檔案。

總結
結構良好的 robots.txt 檔案是管理搜尋引擎如何與您的網站互動的強大工具。透過瞭解如何建立和設定檔案,您可以確保您的網站最佳化以利爬行,同時將敏感或不必要的內容隱藏起來,不讓搜尋引擎爬蟲發現。
Whether managing a personal blog or a large corporate website, a properly implemented robots.txt file can improve your SEO, protect sensitive content, and ensure your site runs smoothly. Regularly review and update the file to align with your site’s growth and changes.