
Controlling what search engines can and can’t crawl is an essential part of managing your online presence. One of the most effective ways to do this is using a robots.txt file. This plain text file tells search engines which parts of your website they can access and which they cannot, helping you guide traffic, protect sensitive content, and improve your site’s SEO.
In this blog, we’ll dive into the importance of a robots.txt file, how to create one, and how to customize it to suit your needs. Whether you’re a beginner or someone with experience managing websites, this guide will help you ensure your site is crawled effectively by search engines.


O que é um ficheiro Robots.txt?
A ficheiro robots.txt is a simple text file placed in the root directory of your website. Its purpose is to instruct web crawlers (such as Google’s Googlebot) on which parts of your site they can visit and index. Following the Norma de exclusão de robôsEste ficheiro ajuda-o a controlar o acesso a diretórios ou páginas específicos, assegurando simultaneamente que o conteúdo crucial permanece disponível para os motores de busca para indexação.


Por exemplo, se o seu sítio Web for www.example.como seu ficheiro robots.txt deve estar localizado em www.example.com/robots.txt.
Como funciona um ficheiro Robots.txt?
A robots.txt file is made up of a series of rules, with each rule specifying whether a certain web crawler (called a “user agent”) can access specific parts of your website. The rules include commands like Não autorizar, Permitire Mapa do sítioque pode restringir ou permitir o acesso a vários URLs.

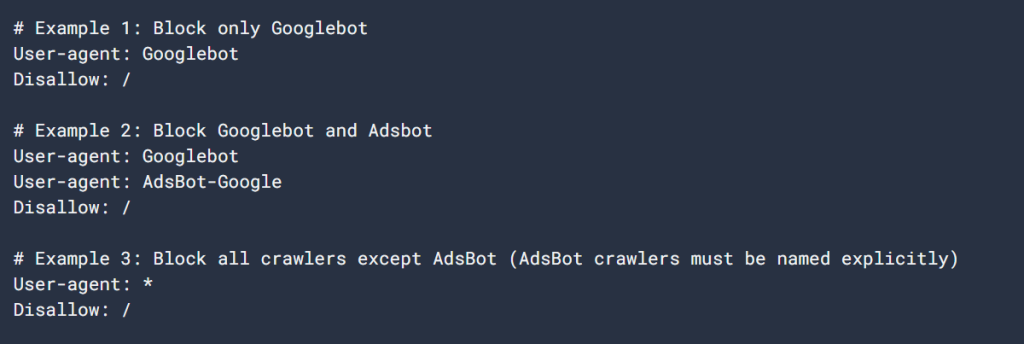
Vejamos um exemplo simples de um ficheiro robots.txt:
Agente do utilizador: Googlebot
Não permitir: /nogooglebot/
Agente do utilizador: *
Permitir: /
Mapa do site: https://www.example.com/sitemap.xmlExplicação do ficheiro:
- Googlebot (Google’s crawler) cannot crawl any URL that starts with https://www.example.com/nogooglebot/.
- Todos os outros agentes de utilizador (marcados com *, which means “all crawlers”) can crawl the entire site.
- O mapa do sítio está localizado em https://www.example.com/sitemap.xml.
Se não existir um ficheiro robots.txt, todos os crawlers podem aceder a todo o sítio Web por predefinição. O ficheiro robots.txt refina essas permissões.
Porque precisa de um ficheiro Robots.txt

A utilização de um ficheiro robots.txt oferece várias vantagens:
- Controlar o rastejamento: Permite-lhe gerir as partes do seu site que são rastreadas pelos motores de busca, reduzindo a carga no seu servidor e evitando que conteúdos sensíveis sejam indexados.
- Melhore a SEO: Pode concentrar os rastreadores dos motores de busca nas páginas mais importantes do seu sítio Web, assegurando que indexam o conteúdo correto para melhorar as suas classificações de pesquisa.
- Proteja conteúdos sensíveis: Embora um ficheiro robots.txt não possa impedir o acesso a dados sensíveis, pode ajudar a ocultar páginas privadas dos rastreadores dos motores de busca, tais como páginas de início de sessão ou secções de administração.
Como criar um ficheiro Robots.txt
Criar um ficheiro robots.txt é fácil e pode fazê-lo utilizando qualquer editor de texto simples, como o Bloco de notas, Editar texto, vi, ou Emacs. Evite utilizar processadores de texto como o Microsoft Word, uma vez que podem introduzir formatação que pode interferir com o funcionamento correto do ficheiro.
1. Crie o ficheiro
Abra o seu editor de texto e guarde um ficheiro com o nome robots.txt. Certifique-se de que está codificado em UTF-8 formato.
2. Adicionar regras
Comece a adicionar regras, especificando a que agentes de utilizador as regras se aplicam e que partes do seu site podem (ou não podem) ser rastreadas.
Eis um exemplo de como bloquear o acesso de todos os Web crawlers a um diretório específico:
Agente do utilizador: *
Não permitir: /private-diretory/3. Carregue o ficheiro
Carregue o robots.txt para o diretório raiz do seu site. Por exemplo, se o seu sítio for www.example.com, o ficheiro deve estar em www.example.com/robots.txt. Se não tiver a certeza de como aceder ao diretório raiz, contacte o seu fornecedor de alojamento.
4. Teste o ficheiro
Depois de carregar o ficheiro, pode testá-lo abrindo um browser em modo privado e navegando para https://www.example.com/robots.txt. Se conseguir ver o ficheiro, isso significa que o ficheiro foi carregado com êxito.
Regras comuns do Robots.txt
Eis algumas regras comuns utilizadas nos ficheiros robots.txt:
1. Bloqueie todos os rastreadores de todo o site


Agente do utilizador: *
Não permitir: /Esta regra impede todos os rastreadores de acederem a todo o Web site. Tenha cuidado com esta regra, uma vez que impede os motores de busca de indexar o seu conteúdo.
2. Permita que todos os rastreadores tenham acesso a todo o site


Agente do utilizador: *
Permitir: /Esta regra permite que todos os rastreadores da Web acedam a todo o seu sítio Web. É o comportamento padrão se não especificar nenhuma regra no seu ficheiro robots.txt.
3. Bloquear um diretório específico
Agente do utilizador: *
Não permitir: /private-diretory/Esta regra impede todos os rastreadores de acederem ao /directorio-privado/. Lembre-se que a barra final indica que tudo o que se encontra dentro do diretório também não é permitido.
4. Permitir um diretório específico, bloquear o resto
Agente do utilizador: *
Não permitir: /
Permitir: /public/Esta regra bloqueia o acesso a todo o site, exceto ao /public/ diretório. Isto é útil quando pretende manter a maior parte do seu sítio privado, mas permite que páginas públicas específicas sejam indexadas.
5. Bloquear uma página específica
Agente do utilizador: *
Não permitir: /useless_page.htmlEsta regra impede todos os rastreadores de acederem a uma página específica do seu site.
6. Especifique um mapa do site
Mapa do sítio: https://www.example.com/sitemap.xmlIncluir um mapa do site no seu ficheiro robots.txt ajuda os motores de busca a localizar e rastrear rapidamente todas as páginas essenciais do seu site.
Melhores práticas para ficheiros Robots.txt
Ao criar o seu ficheiro robots.txt, tenha em mente as seguintes práticas recomendadas:
- Seja específico: Only block pages or directories you don’t want search engines to crawl.
- Utilize o caso correto: As regras são sensíveis a maiúsculas e minúsculas, pelo que Não permita: /Private/ e Não permita: /private/ irá bloquear diferentes diretórios.
- Don’t Use Robots.txt for Sensitive Data: Um ficheiro robots.txt é público e pode ser acedido por qualquer pessoa. Se tiver conteúdos sensíveis, como páginas de início de sessão ou áreas de administração, utilize métodos de autenticação adequados para os proteger em vez de confiar em robots.txt.
- Actualize regularmente: Certifique-se de que o seu ficheiro robots.txt se mantém atualizado com as alterações à estrutura do seu sítio Web.
Como testar e enviar o seu ficheiro Robots.txt

Depois de carregar o seu ficheiro robots.txt, pode testar a sua validade utilizando Testador de robots.txt da Consola de Pesquisa do Google. Esta ferramenta ajuda a garantir que o seu ficheiro está devidamente formatado e que o Google o pode interpretar corretamente.
Para enviar o seu ficheiro robots.txt ao Google:
- Aceda à Consola de Pesquisa do Google.
- Utilize o Testador de Robots.txt para validar o seu ficheiro.
- Uma vez validado, o Google encontrará e utilizará automaticamente o seu ficheiro robots.txt.

Conclusão
Um ficheiro robots.txt bem estruturado é uma ferramenta poderosa para gerir a forma como os motores de busca interagem com o seu site. Ao compreender como criar e configurar o ficheiro, pode garantir que o seu site é optimizado para rastreio, mantendo o conteúdo sensível ou desnecessário escondido dos rastreadores dos motores de busca.
Whether managing a personal blog or a large corporate website, a properly implemented robots.txt file can improve your SEO, protect sensitive content, and ensure your site runs smoothly. Regularly review and update the file to align with your site’s growth and changes.