
Controlling what search engines can and can’t crawl is an essential part of managing your online presence. One of the most effective ways to do this is using a robots.txt file. This plain text file tells search engines which parts of your website they can access and which they cannot, helping you guide traffic, protect sensitive content, and improve your site’s SEO.
In this blog, we’ll dive into the importance of a robots.txt file, how to create one, and how to customize it to suit your needs. Whether you’re a beginner or someone with experience managing websites, this guide will help you ensure your site is crawled effectively by search engines.


Robots.txtファイルとは何ですか?
A robots.txtファイル is a simple text file placed in the root directory of your website. Its purpose is to instruct web crawlers (such as Google’s Googlebot) on which parts of your site they can visit and index. Following the ロボット排除基準このファイルは、重要なコンテンツが検索エンジンにインデックスされるようにしながら、特定のディレクトリやページへのアクセスを制御するのに役立ちます。


例えば、あなたのウェブサイトが www.example.comrobots.txtファイルは次の場所にあります。 www.example.com/robots.txt.
Robots.txtファイルはどのように機能するのですか?
A robots.txt file is made up of a series of rules, with each rule specifying whether a certain web crawler (called a “user agent”) can access specific parts of your website. The rules include commands like 不許可, 許可そして サイトマップこれは、様々なURLへのアクセスを制限または許可することができます。

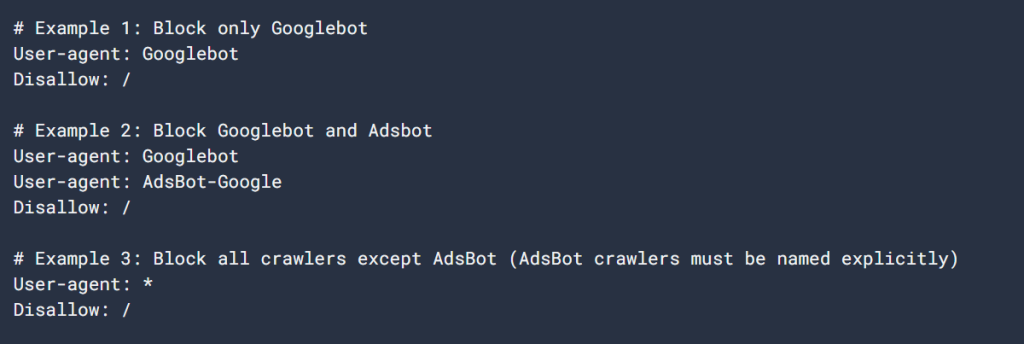
robots.txtファイルの簡単な例を見てみましょう:
ユーザーエージェントGooglebot
許可しない/nogooglebot/
ユーザーエージェント*
許可する/
サイトマップ: https://www.example.com/sitemap.xmlファイルの説明
- グーグルボット (Google’s crawler) cannot crawl any URL that starts with https://www.example.com/nogooglebot/.
- その他のすべてのユーザーエージェント *, which means “all crawlers”) can crawl the entire site.
- サイトのサイトマップは以下にあります。 https://www.example.com/sitemap.xml.
robots.txtファイルが存在しない場合、デフォルトではすべてのクローラーがウェブサイト全体にアクセスできます。robots.txtファイルは、これらのパーミッションを絞り込みます。
Robots.txt ファイルが必要な理由

robots.txtファイルを使用すると、いくつかの利点があります:
- コントロール・クローリング:サイトのどの部分が検索エンジンにクロールされるかを管理することができ、サーバーの負荷を軽減し、機密性の高いコンテンツがインデックスされるのを防ぎます。
- SEO対策:検索エンジンのクローラーをウェブサイトの最も重要なページに集中させ、適切なコンテンツをインデックスさせることで、検索順位を向上させることができます。
- 機密コンテンツの保護:robots.txtファイルは機密データへのアクセスを防ぐことはできませんが、ログインページや管理セクションなどのプライベートなページを検索エンジンのクローラーから隠すことができます。
Robots.txtファイルの作成方法
robots.txtファイルの作成は簡単です。 メモ帳, テキスト編集, ヴィまたは イーマックス.Microsoft Wordのようなワードプロセッサーの使用は避けてください。
1. ファイルの作成
テキストエディタを開き robots.txt.でエンコードされていることを確認します。 UTF-8 形式を採用しています。
2. ルールの追加
ルールが適用されるユーザーエージェントと、クロールが許可される(または許可されない)サイトの部分を指定して、ルールを追加し始めます。
ここでは、すべてのウェブクローラが特定のディレクトリにアクセスするのをブロックする方法の例を示します:
ユーザーエージェント*
不許可/プライベートディレクトリ/3. ファイルのアップロード
をアップロードします。 robots.txt ファイルをウェブサイトのルート・ディレクトリに追加します。例えば、あなたのサイトが www.example.comファイルは www.example.com/robots.txt.ルートディレクトリへのアクセス方法が不明な場合は、ホスティングプロバイダにお問い合わせください。
4. ファイルのテスト
ファイルをアップロードした後、プライベートモードでブラウザを開き、次のページに移動してテストすることができます。 https://www.example.com/robots.txt.ファイルを表示することができれば、ファイルが正常にアップロードされたことを意味します。
一般的なRobots.txtのルール
robots.txtファイルでよく使われるルールをいくつか紹介します:
1. サイト全体からすべてのクローラーをブロック


ユーザーエージェント*
不許可/このルールは、すべてのクローラーがウェブサイト全体にアクセスするのをブロックします。検索エンジンがあなたのコンテンツをインデックスするのを妨げるので、このルールには注意してください。
2. すべてのクローラーにサイト全体へのアクセスを許可


ユーザーエージェント*
許可する/このルールは、すべてのウェブクローラーにウェブサイト全体へのアクセスを許可します。robots.txtファイルに何もルールを指定していない場合のデフォルトの動作です。
3.特定のディレクトリをブロック
ユーザーエージェント*
不許可/プライベートディレクトリ/このルールは、すべてのクローラーが /プライベートディレクトリ.末尾のスラッシュは、そのディレクトリ内のすべてのものも許可されないことを示します。
4. 特定のディレクトリを許可し、それ以外はブロック
ユーザーエージェント*
不許可/
許可する許可: /public/このルールは、以下を除くサイト全体へのアクセスをブロックします。 /パブリック ディレクトリを作成します。これは、サイトの大部分を非公開にしたいが、特定の公開ページがインデックスされるようにしたい場合に便利です。
5. 特定のページをブロック
ユーザーエージェント*
不許可/useless_page.htmlこのルールは、すべてのクローラーがサイトの特定のページにアクセスするのをブロックします。
6. サイトマップの指定
サイトマップ: https://www.example.com/sitemap.xmlrobots.txtファイルにサイトマップを記述することで、検索エンジンがサイト内の重要なページを素早く検索し、クロールしてくれるようになります。
Robots.txtファイルのベストプラクティス
robots.txtファイルを作成する際には、以下のベストプラクティスに留意してください:
- 具体的に: Only block pages or directories you don’t want search engines to crawl.
- 適切なケースを使用:ルールは大文字と小文字を区別します。 不許可/プライベート/ そして 不許可/プライベート/ は異なるディレクトリをブロックします。
- Don’t Use Robots.txt for Sensitive Data:robots.txt ファイルは公開され、誰でもアクセスすることができます。ログインページや管理エリアなど、機密性の高いコンテンツがある場合は、robots.txtに頼るのではなく、適切な認証方法を使って保護してください。
- 定期的な更新:robots.txtファイルは、ウェブサイト構造の変更に合わせて常に最新の状態に保つようにしてください。
Robots.txtファイルのテストと送信方法

robots.txtファイルをアップロードしたら、次のようにしてその有効性をテストできます。 Google Search Consoleのrobots.txtテスター.このツールは、あなたのファイルが適切にフォーマットされ、Googleがそれを正しく解釈できるようにします。
robots.txtファイルをGoogleに送信します:
- Google Search Consoleにアクセスします。
- を使用します。 Robots.txtテスター をクリックしてファイルを検証してください。
- 一度検証されると、Googleは自動的にあなたのrobots.txtファイルを見つけ、使用します。

結論
適切に構造化された robots.txt ファイルは、検索エンジンとサイトのやり取りを管理するための強力なツールです。robots.txtファイルの作成方法と設定方法を理解することで、検索エンジンのクローラーから重要なコンテンツや不要なコンテンツを隠しつつ、クロールに最適化されたサイトにすることができます。
Whether managing a personal blog or a large corporate website, a properly implemented robots.txt file can improve your SEO, protect sensitive content, and ensure your site runs smoothly. Regularly review and update the file to align with your site’s growth and changes.