
Controlling what search engines can and can’t crawl is an essential part of managing your online presence. One of the most effective ways to do this is using a robots.txt file. This plain text file tells search engines which parts of your website they can access and which they cannot, helping you guide traffic, protect sensitive content, and improve your site’s SEO.
In this blog, we’ll dive into the importance of a robots.txt file, how to create one, and how to customize it to suit your needs. Whether you’re a beginner or someone with experience managing websites, this guide will help you ensure your site is crawled effectively by search engines.


¿Qué es un archivo Robots.txt?
A archivo robots.txt is a simple text file placed in the root directory of your website. Its purpose is to instruct web crawlers (such as Google’s Googlebot) on which parts of your site they can visit and index. Following the Norma de exclusión de robots, este archivo le ayuda a controlar el acceso a directorios o páginas específicas al tiempo que garantiza que el contenido crucial siga estando disponible para los motores de búsqueda para su indexación.


Por ejemplo, si su sitio web es www.example.com, su archivo robots.txt debe estar ubicado en www.example.com/robots.txt.
¿Cómo funciona un archivo Robots.txt?
A robots.txt file is made up of a series of rules, with each rule specifying whether a certain web crawler (called a “user agent”) can access specific parts of your website. The rules include commands like No permitir, Permitay Mapa del sitioque puede restringir o permitir el acceso a varias URL.

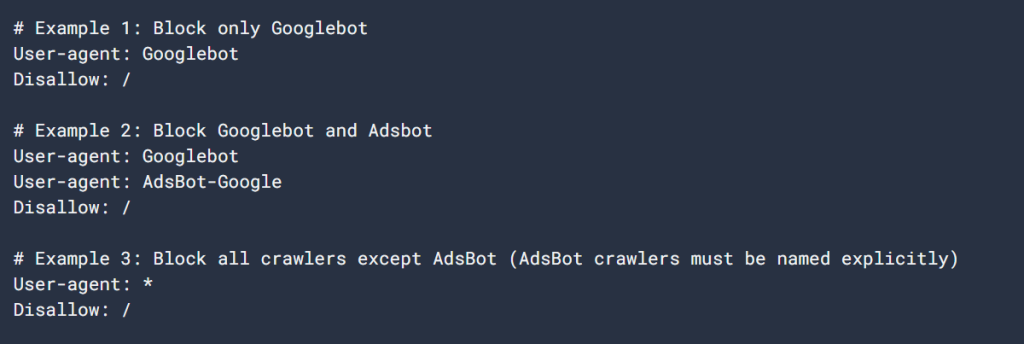
Veamos un ejemplo sencillo de un archivo robots.txt:
Agente de usuario: Googlebot
Disallow: /nogooglebot/
Usuario-agente: *
Permitir: /
Mapa del sitio: https://www.example.com/sitemap.xmlExplicación del archivo:
- Googlebot (Google’s crawler) cannot crawl any URL that starts with https://www.example.com/nogooglebot/.
- Todos los demás agentes de usuario (marcados con *, which means “all crawlers”) can crawl the entire site.
- El mapa del sitio se encuentra en https://www.example.com/sitemap.xml.
Si no existe un archivo robots.txt, todos los rastreadores pueden acceder por defecto a todo el sitio web. El archivo robots.txt refina esos permisos.
Por qué necesita un archivo Robots.txt

El uso de un archivo robots.txt ofrece varias ventajas:
- Controlar el rastreo: Le permite gestionar qué partes de su sitio son rastreadas por los motores de búsqueda, reduciendo la carga de su servidor y evitando que se indexen contenidos sensibles.
- Mejorar el SEO: Puede centrar los rastreadores de los motores de búsqueda en las páginas más esenciales de su sitio web, asegurándose de que indexen el contenido adecuado para mejorar su clasificación en las búsquedas.
- Proteja el contenido sensible: Aunque un archivo robots.txt no puede impedir el acceso a datos sensibles, puede ayudar a ocultar páginas privadas a los rastreadores de los motores de búsqueda, como las páginas de inicio de sesión o las secciones de administración.
Cómo crear un archivo Robots.txt
Crear un archivo robots.txt es fácil, y puede hacerlo utilizando cualquier editor de texto plano como Bloc de notas, TextEdit, vio Emacs. Evite utilizar procesadores de texto como Microsoft Word, ya que pueden introducir formatos que podrían interferir en el correcto funcionamiento del archivo.
1. Crear el archivo
Abra su editor de texto y guarde un archivo llamado robots.txt. Asegúrese de que está codificado en UTF-8 formato.
2. Añadir reglas
Comience a añadir reglas especificando a qué agentes de usuario se aplican y qué partes de su sitio tienen permitido (o prohibido) rastrear.
He aquí un ejemplo de cómo bloquear el acceso de todos los rastreadores web a un directorio específico:
Agente de usuario: *
Disallow: /directorio-privado/3. Cargar el archivo
Cargue el robots.txt al directorio raíz de su sitio web. Por ejemplo, si su sitio es www.example.com, el archivo debe estar en www.example.com/robots.txt. Si no está seguro de cómo acceder al directorio raíz, póngase en contacto con su proveedor de alojamiento.
4. Probar el archivo
Después de cargar el archivo, puede probarlo abriendo un navegador en modo privado y navegando a https://www.example.com/robots.txt. Si puede ver el archivo, significa que se ha cargado correctamente.
Reglas comunes de Robots.txt
Estas son algunas reglas comunes utilizadas en los archivos robots.txt:
1. Bloquear todos los rastreadores de todo el sitio


Agente de usuario: *
Disallow: /Esta regla bloquea el acceso de todos los rastreadores a todo el sitio web. Tenga cuidado con esta regla, ya que impide que los motores de búsqueda indexen su contenido.
2. Permitir a todos los rastreadores el acceso a todo el sitio


Agente de usuario: *
Permitir: /Esta regla permite a todos los rastreadores web acceder a todo su sitio web. Es el comportamiento por defecto si no especifica ninguna regla en su archivo robots.txt.
3. Bloquear un directorio específico
Agente de usuario: *
Disallow: /directorio-privado/Esta regla bloquea el acceso de todos los rastreadores al /directorio-privado/. Recuerde que la barra oblicua final indica que todo lo que se encuentre dentro del directorio también está desautorizado.
4. Permitir un directorio específico, bloquear el resto
Agente de usuario: *
Disallow: /
Permitir: /public/Esta regla bloquea el acceso a todo el sitio excepto al /público/ directorio. Esto es útil cuando desea mantener la mayor parte de su sitio privado pero permitir que determinadas páginas públicas sean indexadas.
5. Bloquear una página específica
Agente de usuario: *
Disallow: /pagina_inservible.htmlEsta regla bloquea el acceso de todos los rastreadores a una página específica de su sitio.
6. Especificar un sitemap
Mapa del sitio: https://www.example.com/sitemap.xmlIncluir un mapa del sitio en su archivo robots.txt ayuda a los motores de búsqueda a localizar y rastrear rápidamente todas las páginas esenciales de su sitio.
Mejores prácticas para los archivos Robots.txt
Al crear su archivo robots.txt, tenga en cuenta las siguientes prácticas recomendadas:
- Sea específico: Only block pages or directories you don’t want search engines to crawl.
- Utilice el caso adecuado: Las reglas distinguen entre mayúsculas y minúsculas, por lo que No permitir: /Privado/ y No permitir: /privado/ bloqueará diferentes directorios.
- Don’t Use Robots.txt for Sensitive Data: Un archivo robots.txt es público y cualquiera puede acceder a él. Si tiene contenido sensible, como páginas de inicio de sesión o áreas de administración, utilice métodos de autenticación adecuados para protegerlas en lugar de confiar en robots.txt.
- Actualícese regularmente: Asegúrese de que su archivo robots.txt se mantiene actualizado con los cambios en la estructura de su sitio web.
Cómo probar y enviar su archivo Robots.txt

Después de cargar su archivo robots.txt, puede comprobar su validez utilizando Comprobador de robots.txt de Google Search Console. Esta herramienta ayuda a garantizar que su archivo tenga el formato adecuado y que Google pueda interpretarlo correctamente.
Para enviar su archivo robots.txt a Google:
- Vaya a Google Search Console.
- Utilice el Comprobador de Robots.txt para validar su archivo.
- Una vez validado, Google encontrará y utilizará automáticamente su archivo robots.txt.

Conclusión
Un archivo robots.txt bien estructurado es una poderosa herramienta para gestionar el modo en que los motores de búsqueda interactúan con su sitio. Si sabe cómo crear y configurar el archivo, podrá asegurarse de que su sitio está optimizado para el rastreo, al tiempo que mantiene oculto el contenido sensible o innecesario a los rastreadores de los motores de búsqueda.
Whether managing a personal blog or a large corporate website, a properly implemented robots.txt file can improve your SEO, protect sensitive content, and ensure your site runs smoothly. Regularly review and update the file to align with your site’s growth and changes.