
Wie man eine robots.txt-Datei schreibt und einreicht

Die Kontrolle darüber, was Suchmaschinen crawlen können und was nicht, ist ein wesentlicher Bestandteil der Verwaltung Ihrer Online-Präsenz. Eine der effektivsten Möglichkeiten, dies zu tun, ist die Verwendung einer robots.txt-Datei. Diese einfache Textdatei teilt den Suchmaschinen mit, auf welche Teile Ihrer Website sie zugreifen können und auf welche nicht. So können Sie den Datenverkehr lenken, sensible Inhalte schützen und die SEO Ihrer Website verbessern.
In diesem Blog erfahren Sie, wie wichtig eine robots.txt-Datei ist, wie Sie eine solche erstellen und wie Sie sie an Ihre Bedürfnisse anpassen können. Egal, ob Sie Anfänger oder jemand mit Erfahrung in der Verwaltung von Websites sind, dieser Leitfaden wird Ihnen helfen, sicherzustellen, dass Ihre Website von Suchmaschinen effektiv gecrawlt wird.
Was ist eine Robots.txt-Datei?
A robots.txt-Datei ist eine einfache Textdatei, die sich im Stammverzeichnis Ihrer Website befindet. Sie dient dazu, Web-Crawlern (wie dem Googlebot) mitzuteilen, welche Teile Ihrer Website sie besuchen und indizieren dürfen. Nach der Roboter Ausschluss StandardMit dieser Datei können Sie den Zugriff auf bestimmte Verzeichnisse oder Seiten kontrollieren und gleichzeitig sicherstellen, dass wichtige Inhalte für Suchmaschinen zur Indizierung verfügbar bleiben.

Wenn Ihre Website zum Beispiel www.example.comsollte sich Ihre robots.txt-Datei in folgendem Verzeichnis befinden www.example.com/robots.txt.
Wie funktioniert eine Robots.txt-Datei?
Eine robots.txt-Datei besteht aus einer Reihe von Regeln, wobei jede Regel angibt, ob ein bestimmter Web-Crawler (ein so genannter "User Agent") auf bestimmte Teile Ihrer Website zugreifen darf. Die Regeln enthalten Befehle wie Nicht zulassen, Erlauben Sie, und Sitemapdie den Zugriff auf verschiedene URLs entweder einschränken oder erlauben kann.
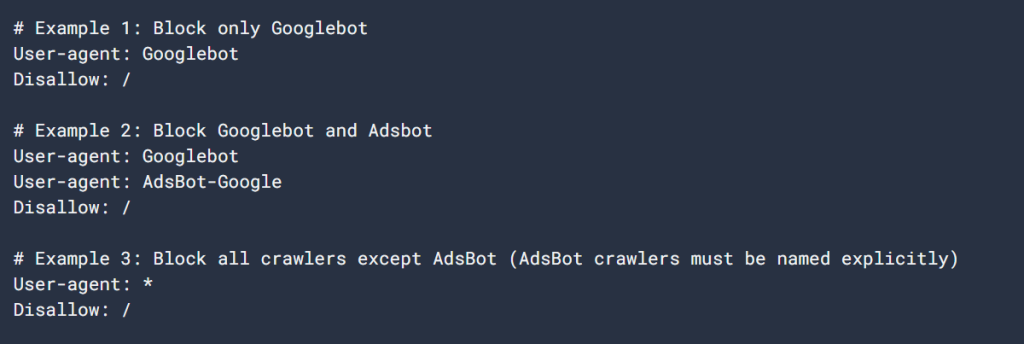
Schauen wir uns ein einfaches Beispiel für eine robots.txt-Datei an:
Benutzer-Agent: Googlebot
Nicht zulassen: /nogooglebot/
Benutzer-Agent: *
Zulassen: /
Sitemap: https://www.example.com/sitemap.xmlErläuterung der Datei:
- Googlebot (der Crawler von Google) kann keine URL crawlen, die mit https://www.example.com/nogooglebot/.
- Alle anderen Benutzeragenten (gekennzeichnet durch *, was soviel bedeutet wie "alle Crawler") können die gesamte Website crawlen.
- Die Sitemap für diese Website finden Sie unter https://www.example.com/sitemap.xml.
Wenn keine robots.txt-Datei vorhanden ist, können alle Crawler standardmäßig auf die gesamte Website zugreifen. Die robots.txt-Datei verfeinert diese Berechtigungen.
Warum Sie eine Robots.txt-Datei benötigen

Die Verwendung einer robots.txt-Datei bietet mehrere Vorteile:
- Kontrolle Crawling: Damit können Sie verwalten, welche Teile Ihrer Website von Suchmaschinen gecrawlt werden, um die Belastung Ihres Servers zu verringern und zu verhindern, dass sensible Inhalte indiziert werden.
- SEO verbessern: Sie können die Crawler der Suchmaschinen auf die wichtigsten Seiten Ihrer Website lenken und so sicherstellen, dass sie die richtigen Inhalte indizieren, um Ihr Suchranking zu verbessern.
- Sensible Inhalte schützen: Eine robots.txt-Datei kann zwar den Zugriff auf sensible Daten nicht verhindern, aber sie kann dabei helfen, private Seiten vor den Crawlern von Suchmaschinen zu verbergen, z. B. Anmeldeseiten oder Verwaltungsbereiche.
Wie man eine Robots.txt-Datei erstellt
Die Erstellung einer robots.txt-Datei ist ganz einfach und kann mit jedem einfachen Texteditor wie Notizblock, TextEdit, vi, oder Emacs. Vermeiden Sie die Verwendung von Textverarbeitungsprogrammen wie Microsoft Word, da diese Formatierungen einführen können, die das ordnungsgemäße Funktionieren der Datei beeinträchtigen könnten.
1. Erstellen Sie die Datei
Öffnen Sie Ihren Texteditor und speichern Sie eine Datei mit dem Namen robots.txt. Vergewissern Sie sich, dass die Kodierung in UTF-8 Format.
2. Regeln hinzufügen
Beginnen Sie mit dem Hinzufügen von Regeln, indem Sie angeben, für welche Benutzeragenten die Regeln gelten und welche Teile Ihrer Website sie crawlen dürfen (oder nicht).
Hier ein Beispiel dafür, wie Sie allen Webcrawlern den Zugriff auf ein bestimmtes Verzeichnis verwehren können:
Benutzer-Agent: *
Nicht zulassen: /privates-verzeichnis/3. Hochladen der Datei
Laden Sie die robots.txt Datei in das Stammverzeichnis Ihrer Website. Wenn Ihre Website zum Beispiel www.example.commuss sich die Datei unter www.example.com/robots.txt. Wenn Sie sich nicht sicher sind, wie Sie auf das Stammverzeichnis zugreifen können, wenden Sie sich an Ihren Hosting-Provider.
4. Testen Sie die Datei
Nachdem Sie die Datei hochgeladen haben, können Sie sie testen, indem Sie einen Browser im privaten Modus öffnen und zu https://www.example.com/robots.txt. Wenn Sie die Datei sehen können, bedeutet dies, dass die Datei erfolgreich hochgeladen wurde.
Allgemeine Robots.txt-Regeln
Hier sind einige gängige Regeln, die in robots.txt-Dateien verwendet werden:
1. Blockieren Sie alle Crawler von der gesamten Website

Benutzer-Agent: *
Nicht zulassen: /Diese Regel blockiert den Zugriff aller Crawler auf die gesamte Website. Seien Sie vorsichtig mit dieser Regel, da sie Suchmaschinen daran hindert, Ihre Inhalte zu indizieren.
2. Allen Crawlern Zugriff auf die gesamte Website gewähren

Benutzer-Agent: *
Zulassen: /Diese Regel erlaubt allen Webcrawlern den Zugriff auf Ihre gesamte Website. Dies ist das Standardverhalten, wenn Sie keine Regeln in Ihrer robots.txt-Datei angeben.
3. Ein bestimmtes Verzeichnis sperren
Benutzer-Agent: *
Nicht zulassen: /privates-verzeichnis/Diese Regel blockiert alle Crawler vom Zugriff auf die /privates-verzeichnis/. Denken Sie daran, dass der abschließende Schrägstrich anzeigt, dass alles innerhalb des Verzeichnisses ebenfalls nicht erlaubt ist.
4. Ein bestimmtes Verzeichnis zulassen, den Rest sperren
Benutzer-Agent: *
Nicht zulassen: /
Zulassen: /public/Diese Regel blockiert den Zugriff auf die gesamte Website mit Ausnahme der /Öffentlich/ Verzeichnis. Dies ist nützlich, wenn Sie den größten Teil Ihrer Website privat halten, aber zulassen möchten, dass bestimmte öffentliche Seiten indiziert werden.
5. Eine bestimmte Seite sperren
Benutzer-Agent: *
Nicht zulassen: /nutzlose_seite.htmlDiese Regel verhindert, dass alle Crawler auf eine bestimmte Seite Ihrer Website zugreifen.
6. Legen Sie eine Sitemap fest
Sitemap: https://www.example.com/sitemap.xmlDie Aufnahme einer Sitemap in Ihre robots.txt-Datei hilft Suchmaschinen, alle wichtigen Seiten Ihrer Website schnell zu finden und zu crawlen.
Bewährte Praktiken für Robots.txt-Dateien
Beachten Sie bei der Erstellung Ihrer robots.txt-Datei die folgenden bewährten Verfahren:
- Spezifisch sein: Blockieren Sie nur Seiten oder Verzeichnisse, die von Suchmaschinen nicht gecrawlt werden sollen.
- Richtigen Fall verwenden: Bei Regeln wird die Groß- und Kleinschreibung beachtet, also Nicht zulassen: /Privat/ und Nicht zulassen: /privat/ werden verschiedene Verzeichnisse blockiert.
- Verwenden Sie Robots.txt nicht für sensible Daten: Eine robots.txt-Datei ist öffentlich und kann von jedem eingesehen werden. Wenn Sie sensible Inhalte haben, wie z.B. Anmeldeseiten oder Verwaltungsbereiche, verwenden Sie geeignete Authentifizierungsmethoden, um diese zu schützen, anstatt sich auf robots.txt zu verlassen.
- Regelmäßig aktualisieren: Stellen Sie sicher, dass Ihre robots.txt-Datei bei Änderungen an Ihrer Website-Struktur auf dem neuesten Stand bleibt.
Wie Sie Ihre Robots.txt-Datei testen und einreichen
Nachdem Sie Ihre robots.txt-Datei hochgeladen haben, können Sie die Gültigkeit der Datei mit Der robots.txt-Tester der Google Search Console. Mit diesem Tool können Sie sicherstellen, dass Ihre Datei angemessen formatiert ist und von Google richtig interpretiert werden kann.
So übermitteln Sie Ihre robots.txt-Datei an Google:
- Gehen Sie zur Google Search Console.
- Verwenden Sie die Robots.txt Tester um Ihre Datei zu validieren.
- Nach der Validierung wird Google Ihre robots.txt-Datei automatisch finden und verwenden.

Fazit
Eine gut strukturierte robots.txt-Datei ist ein leistungsfähiges Instrument zur Verwaltung der Interaktion von Suchmaschinen mit Ihrer Website. Wenn Sie wissen, wie Sie die Datei erstellen und konfigurieren, können Sie sicherstellen, dass Ihre Website für das Crawling optimiert ist und gleichzeitig sensible oder unnötige Inhalte vor den Crawlern der Suchmaschinen verborgen bleiben.
Ganz gleich, ob Sie einen persönlichen Blog oder eine große Unternehmenswebsite verwalten, eine richtig implementierte robots.txt-Datei kann Ihre Suchmaschinenoptimierung verbessern, sensible Inhalte schützen und den reibungslosen Betrieb Ihrer Website gewährleisten. Überprüfen und aktualisieren Sie die Datei regelmäßig, um sie an das Wachstum und die Änderungen Ihrer Website anzupassen.





Responses