
How to write and submit a robots.txt file

Controlling what search engines can and can’t crawl is an essential part of managing your online presence. One of the most effective ways to do this is using a robots.txt file. This plain text file tells search engines which parts of your website they can access and which they cannot, helping you guide traffic, protect sensitive content, and improve your site’s SEO.
In this blog, we’ll dive into the importance of a robots.txt file, how to create one, and how to customize it to suit your needs. Whether you’re a beginner or someone with experience managing websites, this guide will help you ensure your site is crawled effectively by search engines.
What is a Robots.txt File?
A robots.txt file is a simple text file placed in the root directory of your website. Its purpose is to instruct web crawlers (such as Google’s Googlebot) on which parts of your site they can visit and index. Following the Robots Exclusion Standard, this file helps you control access to specific directories or pages while ensuring that crucial content remains available to search engines for indexing.

For instance, if your website is www.example.com, your robots.txt file should be located at www.example.com/robots.txt.
How Does a Robots.txt File Work?
A robots.txt file is made up of a series of rules, with each rule specifying whether a certain web crawler (called a “user agent”) can access specific parts of your website. The rules include commands like Disallow, Allow, and Sitemap, which can either restrict or allow access to various URLs.
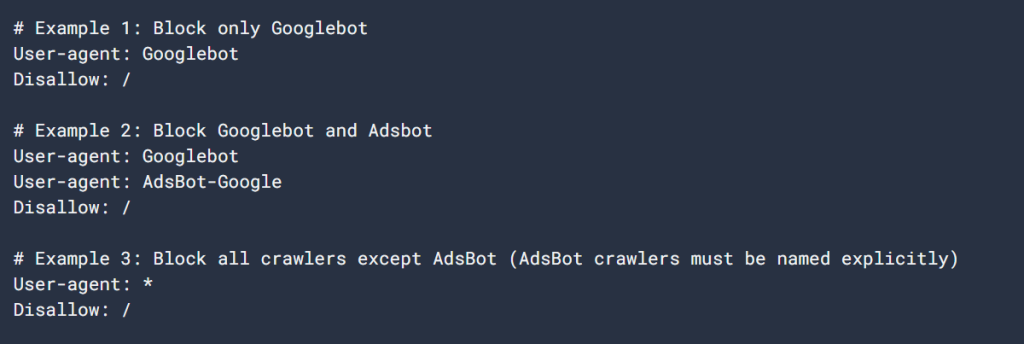
Let’s look at a simple example of a robots.txt file:
User-agent: Googlebot
Disallow: /nogooglebot/
User-agent: *
Allow: /
Sitemap: https://www.example.com/sitemap.xmlExplanation of the file:
- Googlebot (Google’s crawler) cannot crawl any URL that starts with https://www.example.com/nogooglebot/.
- All other user agents (marked by *, which means “all crawlers”) can crawl the entire site.
- The sitemap for the site is located at https://www.example.com/sitemap.xml.
If a robots.txt file does not exist, all crawlers can access the entire website by default. The robots.txt file refines those permissions.
Why You Need a Robots.txt File

Using a robots.txt file offers several advantages:
- Control Crawling: It allows you to manage which parts of your site are crawled by search engines, reducing the load on your server and preventing sensitive content from being indexed.
- Improve SEO: You can focus search engine crawlers on the most essential pages of your website, ensuring they index the right content to improve your search rankings.
- Protect Sensitive Content: While a robots.txt file can’t prevent access to sensitive data, it can help hide private pages from search engine crawlers, such as login pages or admin sections.
How to Create a Robots.txt File
Creating a robots.txt file is easy, and you can do it using any plain text editor such as Notepad, TextEdit, vi, or Emacs. Avoid using word processors like Microsoft Word, as they can introduce formatting that might interfere with the proper functioning of the file.
1. Create the File
Open your text editor and save a file named robots.txt. Ensure that it is encoded in UTF-8 format.
2. Add Rules
Begin adding rules by specifying which user agents the rules apply to and which parts of your site they are allowed (or disallowed) to crawl.
Here’s an example of how to block all web crawlers from accessing a specific directory:
User-agent: *
Disallow: /private-directory/3. Upload the File
Upload the robots.txt file to the root directory of your website. For example, if your site is www.example.com, the file must be at www.example.com/robots.txt. If you are unsure how to access the root directory, contact your hosting provider.
4. Test the File
After uploading the file, you can test it by opening a browser in private mode and navigating to https://www.example.com/robots.txt. If you can view the file, it means the file has been uploaded successfully.
Common Robots.txt Rules
Here are some common rules used in robots.txt files:
1. Block All Crawlers from the Entire Site

User-agent: *
Disallow: /This rule blocks all crawlers from accessing the entire website. Be cautious with this rule, as it prevents search engines from indexing your content.
2. Allow All Crawlers Access to the Entire Site

User-agent: *
Allow: /This rule allows all web crawlers to access your entire website. It is the default behaviour if you do not specify any rules in your robots.txt file.
3. Block a Specific Directory
User-agent: *
Disallow: /private-directory/This rule blocks all crawlers from accessing the /private-directory/. Remember that the trailing slash indicates that everything inside the directory is also disallowed.
4. Allow a Specific Directory, Block the Rest
User-agent: *
Disallow: /
Allow: /public/This rule blocks access to the entire site except for the /public/ directory. This is useful when you want to keep most of your site private but allow specific public pages to be indexed.
5. Block a Specific Page
User-agent: *
Disallow: /useless_page.htmlThis rule blocks all crawlers from accessing a specific page on your site.
6. Specify a Sitemap
Sitemap: https://www.example.com/sitemap.xmlIncluding a sitemap in your robots.txt file helps search engines quickly locate and crawl all the essential pages on your site.
Best Practices for Robots.txt Files
When creating your robots.txt file, keep the following best practices in mind:
- Be Specific: Only block pages or directories you don’t want search engines to crawl.
- Use Proper Case: Rules are case-sensitive, so Disallow: /Private/ and Disallow: /private/ will block different directories.
- Don’t Use Robots.txt for Sensitive Data: A robots.txt file is public and can be accessed by anyone. If you have sensitive content, such as login pages or admin areas, use proper authentication methods to protect them instead of relying on robots.txt.
- Update Regularly: Make sure your robots.txt file stays up-to-date with changes to your website structure.
How to Test and Submit Your Robots.txt File
After uploading your robots.txt file, you can test its validity using Google Search Console’s robots.txt tester. This tool helps ensure that your file is appropriately formatted and that Google can interpret it correctly.
To submit your robots.txt file to Google:
- Go to Google Search Console.
- Use the Robots.txt Tester to validate your file.
- Once validated, Google will automatically find and use your robots.txt file.

Conclusion
A well-structured robots.txt file is a powerful tool for managing how search engines interact with your site. By understanding how to create and configure the file, you can ensure your site is optimized for crawling while keeping sensitive or unnecessary content hidden from search engine crawlers.
Whether managing a personal blog or a large corporate website, a properly implemented robots.txt file can improve your SEO, protect sensitive content, and ensure your site runs smoothly. Regularly review and update the file to align with your site’s growth and changes.






Responses